AI for Audio, Speech, and Natural Language Processing, including the following topics: multi-modal large language models, foundation models for audio and speech AI, audio-visual multi-modal AI, speech AI systems for health applications, and secure and trustworthy speech AI.
My recent research can be summarized in my talk at the 2024 MIT Imagination In Action Summit.
Bio
I am a Member of Technical Staff at xAI. I'm recognized as a core contributor to Grok Advanced Voice Mode, the first author of LTU, the first audio large language model, and the first author of AST, a widely used audio classifier.
Before joining xAI, I was a Research Scientist at the MIT CSAIL Spoken Language Systems Group (SLS), working with Dr. James Glass. Prior to that, I earned my Ph.D. in Computer Science from the University of Notre Dame, where I was supervised by Dr. Christian Poellabauer. In the summer of 2019, I was an Applied Scientist Intern working on clinical text mining with the AWS Comprehend Medical team, supervised by Mohammed Khalilia and Parminder Bhatia. Before coming to Notre Dame, I received my B.Sc. degree in Electrical Engineering (Biomedical Engineering major) from Fudan University in 2015. My research advisors were Dr. Yuanyuan Wang (ultrasound image denoising) and Dr. Yuedong Xu (network science).
Education
2020.7 Ph.D., Computer Science and Engineering, University of Notre Dame, IN, USA (GPA: 4.0/4.0)
2024.8 - Member of Technical Staff, xAI Corp., Palo Alto, USA
2023.8 - 2024.8 Research Scientist II, Massachusetts Institute of Technology, Cambridge, USA
2020.8 - 2023.7 Postdoc Research Associate, Massachusetts Institute of Technology, Cambridge, USA
2015.8 - 2020.7 Graduate Research Assistant, University of Notre Dame, Notre Dame, USA
2019.5 - 2019.8 Applied Scientist Intern, Amazon Web Service, Seattle, USA
2014.6 - 2015.7 Undergraduate Research Assistant, Fudan University, Shanghai, China
2012.7 - 2012.8 Intern, Philips Healthcare, Shanghai, China
Awards
ASRU 2023 Best Paper Finalist (top 3% paper, 12/435)
ICASSP 2023 Outstanding Reviewer
INTERSPEECH 2019 Best Student Paper Award Nomination
Depression Detection Challenge Winner, the 7th ACM Multimedia Audio/Visual Emotion Challenge and Workshop (AVEC 2017)
IJCAI, ISCA, ICHI, NSF Travel Grant
Outstanding Graduate of Fudan University (2015), Fudan First Prize Scholarship (Top 3%, 2014), Outstanding Student of Dept. of Information Technology (2013), Outstanding Student of Fudan University (2012)
Publications
2025
CAV-MAE Sync: Improving Contrastive Audio-Visual Mask Autoencoders via Fine-Grained Alignment Edson Araujo, Andrew Rouditchenko, Yuan Gong, Saurabhchand Bhati, Samuel Thomas, Brian Kingsbury, Leonid Karlinsky, Rogerio Feris, James R. Glass, Hilde Kuehne Proceedings of the 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, June 2025 (CVPR 2025, accepted, to appear)
UniWav: Towards Unified Pre-training for Speech Representation Learning and Generation Alexander H. Liu, Sang-gil Lee, Chao-Han Huck Yang, Yuan Gong, Yu-Chiang Frank Wang, James R. Glass, Rafael Valle, Bryan Catanzaro
Proceedings of the 13th International Conference on Learning Representations, Singapore, May 2025 (ICLR 2025, accepted, to appear) Paper
AER-LLM: Ambiguity-aware Emotion Recognition Leveraging Large Language Models Xin Hong, Yuan Gong, Vidhyasaharan Sethu, Ting Dang Proceedings of the 50th International Conference on Acoustics, Speech, & Signal Processing, Hyderabad, India, April 2025 (ICASSP 2025) Paper
Revise, Reason, and Recognize: LLM-Based Emotion Recognition via Emotion-Specific Prompts and ASR Error Correction Yuanchao Li, Yuan Gong, Chao-Han Huck Yang, Peter Bell, Catherine Lai Proceedings of the 50th International Conference on Acoustics, Speech, & Signal Processing, Hyderabad, India, April 2025 (ICASSP 2025) Paper
2024
Listen, Think, and Understand Yuan Gong, Hongyin Luo, Alexander H. Liu, Leonid Karlinsky, and James Glass
Proceedings of the 12th International Conference on Learning Representations, Vienna, Austria, May 2024 (ICLR 2024) Paper | Interactive Demo | Code | 5-Min Video (Chrome only)
Whisper-Flamingo: Integrating Visual Features into Whisper for Audio-Visual Speech Recognition and Translation
Andrew Rouditchenko, Yuan Gong, Samuel Thomas, Leonid Karlinksy, Hilde Kuehne, Rogerio Feris, James Glass
Proceedings of the 25th Conference of the International Speech Communication Association, Kos Island, Greece, September 2024 (Interspeech 2024) Paper | Code
Automatic Prediction of Amyotrophic Lateral Sclerosis Progression using Longitudinal Speech Transformer
Liming Wang, Yuan Gong, Nauman Dawalatabad, Marco Vilela, Katerina Placek, Brian Tracey, Yishu Gong, Alan Premasiri, Fernando Vieira, James Glass
Proceedings of the 25th Conference of the International Speech Communication Association, Kos Island, Greece, September 2024 (Interspeech 2024) Paper
Natural Language Embedded Programs for Hybrid Language Symbolic Reasoning
Tianhua Zhang, Jiaxin Ge, Hongyin Luo, Yung-Sung Chuang, Mingye Gao, Yuan Gong, Xixin Wu, Yoon Kim, Helen Meng, and James Glass
Proceedings of Findings of the 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Mexico, June 2024 (Findings of NAACL 2024) Paper | Code | MIT News
DASS: Distilled Audio State Space Models Are Stronger and More Duration-Scalable Learners
Saurabhchand Bhati, Yuan Gong, Leonid Karlinsky, Hilde Kuehne, Rogério Feris, and James Glass Proceedings of the 2024 IEEE Spoken Language Technology Workshop, Macao, China, December 2024 (SLT 2024) Paper
Large language model based generative error correction: A challenge and baselines for speech recognition, speaker tagging, and emotion recognition Chao-Han Huck Yang, Taejin Park, Yuan Gong, Yuanchao Li, Zhehuai Chen, Yen-Ting Lin, Chen Chen, Yuchen Hu, Kunal Dhawan, Piotr Żelasko, Chao Zhang, Yun-Nung Chen, Yu Tsao, Jagadeesh Balam, Boris Ginsburg, Sabato Marco Siniscalchi, Eng Siong Chng, Peter Bell, Catherine Lai, Shinji Watanabe, Andreas Stolcke Proceedings of the 2024 IEEE Spoken Language Technology Workshop, Macao, China, December 2024 (SLT 2024) Paper
2023
Joint Audio and Speech Understanding(top 3% paper, best paper finalist) Yuan Gong, Alexander H. Liu, Hongyin Luo, Leonid Karlinsky, and James Glass
Proceedings of the 2023 IEEE Automatic Speech Recognition and Understanding Workshop, Taipei, December 2023 (ASRU 2023) Paper | Interactive Demo | Code | Poster
SAIL: Search-Augmented Instruction Learning
Hongyin Luo, Yung-Sung Chuang, Yuan Gong, Tianhua Zhang, Yoon Kim, Xixin Wu, Helen Meng, and James Glass
Proceedings of Findings of the 2023 Conference on Empirical Methods in Natural Language Processing (Findings of EMNLP 2023) Paper | Code
Whisper-AT: Noise-Robust Automatic Speech Recognizers are Also Strong General Audio Event Taggers Yuan Gong, Sameer Khurana, Leonid Karlinsky, and James Glass
Proceedings of the 24th Conference of the International Speech Communication Association, Dublin, Ireland, August 2023 (Interspeech 2023) Paper | Code | Interactive Demo | Poster | 中文博客介绍 | 中文代码解读
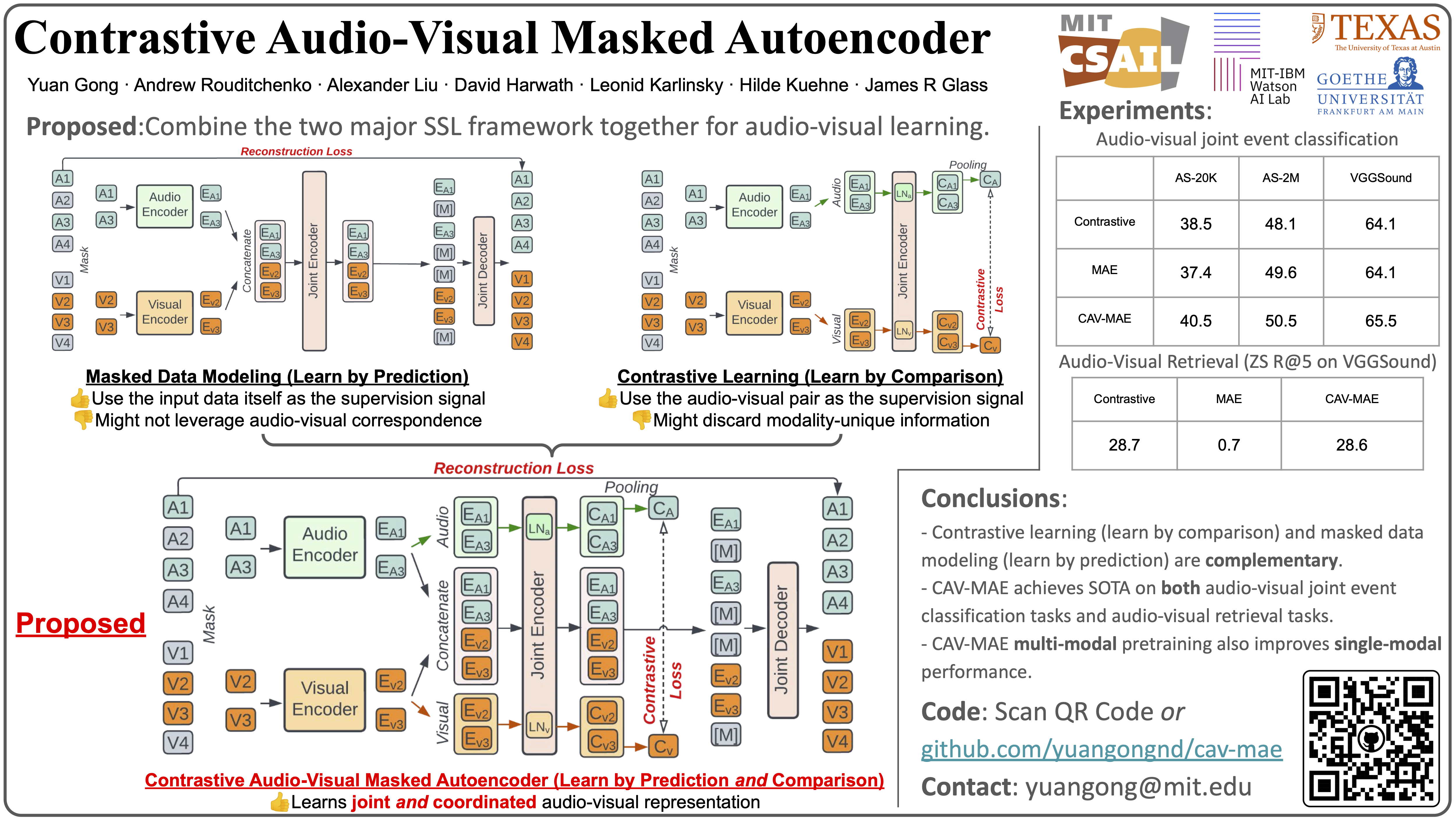
Contrastive Audio-Visual Masked Autoencoder(notable-top-25% paper) Yuan Gong, Andrew Rouditchenko, Alexander H. Liu, David Harwath, Leonid Karlinsky, Hilde Kuehne, and James Glass
Proceedings of the 11th International Conference on Learning Representations, Kigali, Rwanda, May 2023 (ICLR 2023) Paper | Code | Video | Slides | Poster | MIT News
Improving Computational Efficiency of Voice Anti-Spoofing Models
Jian Yang, Bryan Ning Xia, John Bailey, Yuan Gong, John Michael Templeton, and Christian Poellabauer
Proceedings of the 2023 IEEE 20th International Conference on Mobile Ad Hoc and Smart Systems (MASS 2023) Paper | Code
2022
UAVM: Towards Unifying Audio and Visual Models Yuan Gong, Alexander H. Liu, Andrew Rouditchenko, and James Glass
IEEE Signal Processing Letters, 2022 Paper | Code
Detecting Dementia from Long Neuropsychological Interviews
Nauman Dawalatabad, Yuan Gong, Sameer Khurana, Rhoda Au, and James Glass
Proceedings of Findings of the 2022 Conference on Empirical Methods in Natural Language Processing (Findings of EMNLP 2022), Abu Dhabi, December 2022 Paper
Vocalsound: A Dataset For Improving Human Vocal Sounds Recognition Yuan Gong, Jin Yu, and James Glass
Proceedings of the 47th International Conference on Acoustics, Speech, & Signal Processing (ICASSP 2022), Singapore, May 2022 Paper | Dataset & Code | Video | Slides
Transformer-Based Multi-Aspect Multi-Granularity Non-Native English Speaker Pronunciation Assessment Yuan Gong, Ziyi Chen, Iek-Heng Chu, Peng Chang, and James Glass
Proceedings of the 47th International Conference on Acoustics, Speech, & Signal Processing (ICASSP 2022), Singapore, May 2022 Paper | Code | Video | Slides | Blog in Chinese
SSAST: Self-Supervised Audio Spectrogram Transformer Yuan Gong, Cheng-I Jeff Lai, Yu-An Chung, and James Glass
Proceedings of the 36th AAAI Conference on Artificial Intelligence (AAAI 2022), Vancouver, Canada, February-March 2022 Paper | Code | Slides
2021
AST: Audio Spectrogram Transformer Yuan Gong, Yu-An Chung, and James Glass
Proceedings of the 22nd Conference of the International Speech Communication Association (Interspeech 2021), Brno, Czech Republic, August-September 2021 Paper | Code | Talk | Blog in Chinese
PSLA: Improving Audio Tagging with Pretraining, Sampling, Labeling, and Aggregation Yuan Gong, Yu-An Chung, and James Glass
IEEE Transactions on Audio, Speech and Language Processing, 2021 Paper | Code | Video | Slides | Blog in Chinese
2020
Detecting Replay Attacks Using Multi-Channel Audio: A Neural Network-Based Method Yuan Gong, Jian Yang, and Christian Poellabauer
IEEE Signal Processing Letters, 2020 Paper | Code
2019
Second-order Non-local Attention Networks for Person Re-identification
Bryan Xia, Yuan Gong, Yizhe Zhang, and Christian Poellabauer
Proceedings of the 2019 International Conference on Computer Vision (ICCV 2019), Seoul, Korea, October-November 2019 Paper | Blog
ReMASC: Realistic Replay Attack Corpus for Voice Controlled Systems (best student paper award nomination) Yuan Gong, Jian Yang, Jacob Huber, Mitchell MacKnight, Christian Poellabauer
Proceedings of the 20th Conference of the International Speech Communication Association (Interspeech 2019), Graz, Austria, September 2019 Paper | Dataset
Real-time Adversarial Attacks Yuan Gong, Boyang Li, Christian Poellabauer, and Yiyu Shi
Proceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI 2019), Macao, China, August 2019. Paper |
Code |
Media
2018
Deep Obfuscation: Precise Masking of Sensitive Information to Protect Against Machine Learning Adversaries (Poster) Yuan Gong and Christian Poellabauer
Proceedings of the 2018 Annual Computer Security Applications Conference Poster Session, San Juan, Puerto Rico, December 2018.
Crafting Adversarial Examples For Speech Paralinguistics Applications Yuan Gong and Christian Poellabauer
Proceedings of the DYnamic and Novel Advances in Machine Learning and Intelligent Cyber Security (DYNAMICS) Workshop, San Juan, Puerto Rico, December 2018. Paper
Impact of Aliasing on Deep CNN-Based End-to-End Acoustic Models Yuan Gong, Kevin Shin, and Christian Poellabauer
Proceedings of the 19th Conference of the International Speech Communication Association (Interspeech 2018), Hyderabad, India, September 2018. Paper
Improving LIWC Using Soft Word Matching (Poster) Yuan Gong, Hasini Yatawatte, Christian Poellabauer, Sandra Schneider, and Susan Latham
Proceedings of the 9th ACM Conference on Bioinformatics, Computational Biology, and Health Informatics (ACM-BCB), Washington, DC, August-September 2018. Paper
Automatic Autism Spectrum Disorder Detection Using Everyday Vocalizations Captured by Smart Devices Yuan Gong and Christian Poellabauer
Proceedings of the 9th ACM Conference on Bioinformatics, Computational Biology, and Health Informatics (ACM-BCB), Washington, DC, August-September 2018. Paper
Protecting Voice Controlled Systems Using Sound Source Identification Based on Acoustic Cues Yuan Gong and Christian Poellabauer
Proceedings of the 27th International Conference on Computer Communications and Networks (ICCCN), Hangzhou, China, July-August 2018. Paper
An Overview of Vulnerabilities of Voice Controlled Systems Yuan Gong and Christian Poellabauer
Proceedings of the 1st International Workshop on Security and Privacy for the Internet-of-Things (IoTSec), Orlando, FL, April 2018. Paper
2017
Topic Modeling Based Multi-modal Depression Detection (depression challenge winner) Yuan Gong and Christian Poellabauer
Proceedings of the 7th Audio/Visual Emotion Challenge and Workshop (AVEC) in conjunction with ACM Multimedia (ACM-MM), Mountain View, CA, October 2017. Paper
Continuous Assessment of Children's Emotional States using Acoustic Analysis Yuan Gong and Christian Poellabauer
Proceedings of the 5th IEEE International Conference on Healthcare Informatics (ICHI), Park City, UT, August 2017. Paper
2015
A Smart Low-Power-Consumption ECG Monitor Based on MSP430F5529 and CC2540 (winner of the 2014 TI national (China) biomedical device design contest) Yuan Gong, Jin Cao, Zehui Luo, Guohui Zhou
Chinese Journal of Medical Instrumentation 39.4, 2015 Paper
Preprint
CMKD: CNN/Transformer-Based Cross-Model Knowledge Distillation for Audio Classification Yuan Gong, Sameer Khurana, Andrew Rouditchenko, and James Glass Paper
From Audio Perception to Understanding: A Path Towards Audio AGI Amazon GenAI, 4/24/2024.
General Audio Processing: Perception, Understanding, and Generation MIT 6.8620/HST.728 Spoken Language Processing (Guest Lecture). 4/16/2024. [slides]
How We Evaluate Our Audio and Speech Large Language Model? ASRU SPARKS Workshop, 12/16/2023. [slides]
Recent Progress of MIT SLS's Research on Audio Classification and Understanding (two-hour tutorial talk) Amazon Alexa, 12/15/2023. [slides]
Contrastive Audio-Visual Masked Autoencoder IBM, 7/28/2023; Hong Kong University of Science and Technology, 10/11/2023.
Large Language Models that Listen Takeda, 5/30/2023; Signify, 7/21/2023.
Introduction of Audio Spectrogram Transformer - Architecture, Training, and Pre-training Mitsubishi Electric Research Laboratories, 6/8/2022; ByteDance, 6/14/2022; Adobe, 7/12/2022.
Introduction of Audio Spectrogram Transformer - Architecture, Training, and Pre-training AI Time. 5/26/2022. [video in Mandarin] [slides]
General Audio Processing MIT 6.345/HST.728 Spoken Language Processing (Guest Lecture). 4/19/2022.
Audio Spectrogram Transformer MIT Embodied Intelligence Seminar. 10/14/2021. [video]
Audio Spectrogram Transformer for Audio Scene Analysis ISCA SIGML Seminar. 6/16/2021. [video] [slides]
Win the cat and mouse game: ensuring the security of the speech processing systems to real-world threats University of Notre Dame CSE60641 (Guest Lecture). 10/31/2019. [slides]
Speech Processing: Machine Learning Approaches, Novel Applications, and New Security Concerns University of Notre Dame CSE60641 (Guest Lecture, Sole Instructor). 9/20/2018. [slides]
Contact
Please feel free to reach out (yuangong@mit.edu) if you have any questions about my work. I do not use WeChat. As a research scientist, I am not involved in student/researcher recruitment at CSAIL, please contact a PI for such inquiries.
 Yuan Gong
Yuan Gong
{kind=link}
{kind=link}
{kind=link}